Lisplab is a mathematics and matrix library in Common Lisp released under the GNU General Public License (GPL) and hosted at common-lisp.net. Lisplab was originally based on code from Matlisp but it has moved quite far from the original code mass.
The main purpose of Lisplab is to to integrate all kinds of mathematical capabilities into one framework. Lisplab is heavily based on CLOS.
Lisplab containsThe part of Lisplab which is most mature is the matrix and linear algebra, which should provide a good basis for matrix based modelling.
Lisplab is installed by asdf. BLAS, LAPACK, and FFTW must be installed separately. The external libraries make Lisplab more powerful, but it has a lot of capabilities and good performance without them. Lisplab is mainly ANSI-compliant and does not depend on other Common Lisp projects but it has so far only been tested on SBCL, so for other Lisps you must expect some hacking to make it build.
See manual for details.
> (require :lisplab)and use it by
> (use-package :ll-user)When compiling for the first time you must have *read-default-float-format* set to 'double-float because the generated slatec code requires it. When started, you can for example square the elements:
LL-USER> (.^ #md((1 2) (3 4)) 2)
#md(( 1.000 4.000 )
( 9.000 16.00 ))
The read macro #md creates double-floats matrices,
and #mz create complex double float matrices.
Untyped matrices are created with #mm.
Common operations are
.+ .- .* ./ .^ .expt .sqrt .log .sgn .sin .cos .tan .asin .acos .atan .sinh .cosh .tanh .asinh .acosh .atanh .besj .besy .besi .besk .besh .gamma .erf .erfc mref vref size dim rows cols rank mmap make-matrix-instance dnew dmat dcol drow znew zmat zcol zrow mnew mmat mcol mrow mmax mmin circ-shift pad-shift m* m/ minv mtp mct eivenvalues eigenvectors LU-factor lin-solve dlmread dlmwrite pswrite pgmwrite export-list import-list fftw1 ifftw1 fftw2 ifftw2 fft-shift ifft-shift rk4 euler w/infix
Performance should be quite good (at least on SBCL) since Lisplab's main usage has been to solve partial differential equations in physics.
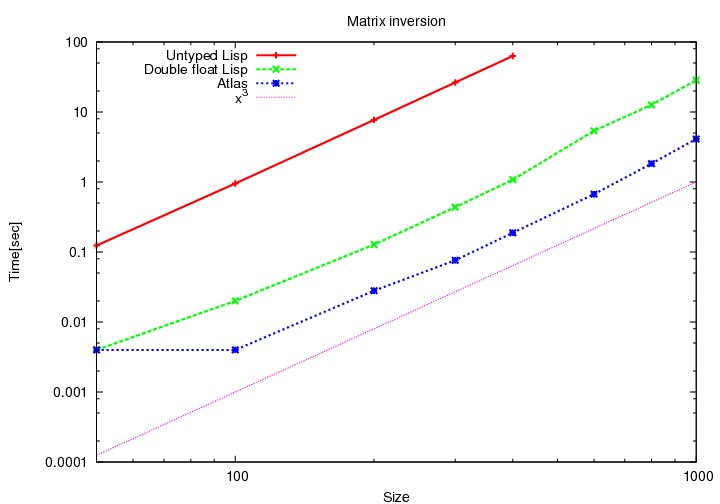
The graph below compares matrix inversion scalability between the Lapack FFI, and two native implementations: one typed and one untyped. All graphs scale as O(n3), but we see that the untyped version is hopelessly slow, while the typed version is a factor 10 slower than Lapack, which is rather good, and means that it is usable for high performance computing.
The manual is in html and in pdf.
Module documentation is generated with Tinaa.
Tarballs are here.
You can browse the svn repository or check out the latest development tree from anonymous svn,
% svn checkout svn://common-lisp.net/project/lisplab/svn lisplabor if you want just the latest version,
% svn checkout svn://common-lisp.net/project/lisplab/svn/trunk lisplab